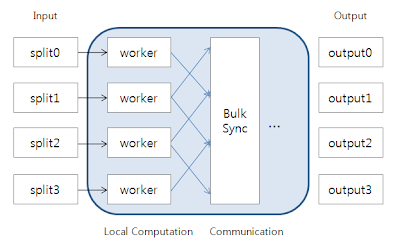
Each worker will process the data fragments stored locally. And then, We can do bulk synchronization using collected communication data. The 'Computation' and 'Bulk synchronization' can be performed iteratively, Data for synchronization can be compressed to reduce network usage.
Plainly, It aims to improve the performance of traverse operations in Graph computing. For example, to explores all the neighboring nodes from the root node using Map/Reduce (FYI, Breadth-First Search (BFS) & MapReduce), We need a lot of iterations to get next vertex per-hop time.
If (same condition as before) do BFS using Hamburg, It will cause a lowering the cost of iterations. Let's assume the graph looks like presented below:

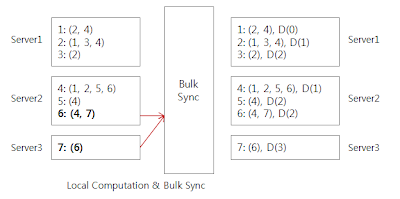
The graph was stored in Hbase on distributed system as above. The root is 1. Then, we need only one 'Bulk synchronization' between server2 and server3 with Hamburg. Rests will be calculated on local machine.
Almost graph algorithms are similar with this case.
Updated - 26 August, 2009 : See also, Inference anatomy of the Google Pregel


Server2 needs to tell Server3 that the vertex 6 distance is 2 so that Server3 can assign distance 3 for vertex 7.
ReplyDeleteSince Server2 can only see partial view for vertex 2 neighbors, I think Server2 also has to tell Server1 about the distance of vertex 2 (which is 2). Then Server1 decides the final distance of vertex 2 (which is 1).
Or the other way around: Server1 already decides the distance of vertex 2 is 1 and needs to tell Server2 about it (since from Server2 point of view, the disntance of vertex 2 is 2).
Eitherway, Server1 and Server2 has to communicate, isn't it?
The start node assumed as a vertext 1. Hence, Server1's processing will be locally done w/o any communicate. There is one communication between Server2 and Server3.
ReplyDeleteNice info regarind graph computing framework on Hadoop my sincere thanks for sharing please continue to share this post
ReplyDeleteHadoop Training in Chennai
The share you really give us excitement. Thanks for your sharing. If you feel tired at work or study try to participate in our games to bring the most exciting feeling. Thank you!
ReplyDeletePython Online Training | Learn Python Online
niceblog
ReplyDeleteVery good blog helpful to everyone AWS training in bangalore
ReplyDeleteHadoop training in bangalore
Tableau training in bangalore
PHP training in bangalore
Android training in bangalore
Digital marketing training in bangalore
Nice blogiteanz
ReplyDeletemachine learning training in bangalore
DEvops Training in Bnagalore
powershell training in bangalore
Iot Training in Bnagalore
Nice Article Keep Posting it
ReplyDeleteIot training in Bangalore
Iteanz
Nice blog
ReplyDeletejquery interview questions
sql interview questions
Nice blog
ReplyDeletetalend training
docker training
Thanks for sharing this blog, I am reading your post from the beginning, it was so interesting to read. Visit for
ReplyDeleteWeb Design Company in Delhi
lg fridge repair in gurgaon
ReplyDeleteTHANKS FOR INFORMATION
ReplyDeleteyou can search low-cost website with high-quality website functions.
Today Join Us
Call: +91 - 8076909847
website designing company in india
levantro
best interior designer in delhi
livewebindia
best website designing company in delhi
seo company delhi
Best It Service Provider:
1. Website Designing And Development.
2. SEO Services.
3. Software Development.
4. Mobile App Development.
Great information
ReplyDeletedigital marketing courses in Marathahalli with placement
digital marketing training in Marathahalli
seo training in Marathahalli
Great post with wonderful piece of information. I really like it. Thanks for sharing.
ReplyDeleteTally Course in Chennai
Tally Training in Chennai
Mobile Testing Training in Chennai
Mobile Testing Course in Chennai
Manual Testing Training in Chennai
Manual Testing Courses in Chennai
Tally Course in Adyar
Tally Course in Velachery
Hi,
ReplyDeleteThanks for sharing such a useful information,
If anyone is looking out for a SEO service in Delhi,NCR then there is only one name which you can trust i;e,Nexcuit.com is one of the best SEO company in Delhi. Be Digitally Visible at the Exact Right time you are Being Searched For! We are the pioneer seo company in Delhi and we implement tactical planning and positioning to make stronger your brand presence worldwide and offer the essential impetus to bring up rankings. Call @ 919910326510 and get more insights concerning their charges, Get best SEO Package from the Best SEO Company in Delhi NCR
seo services in India
seo service in Delhi
seo company in Delhi
Very interesting information and this is very useful in my future. Please update them.
ReplyDeleteExcel Training in Chennai
Excel classes in Chennai
Tableau Training in Chennai
Oracle Training in Chennai
Linux Training in Chennai
Spark Training in Chennai
Embedded System Course Chennai
Oracle DBA Training in Chennai
Excel Training in Vadapalani
Excel Training in Thiruvanmiyur
AutoCAD training in Coimbatore
ReplyDeleteArchiCAD training in Coimbatore
AutoCAD RCC Detailing training in Coimbatore
Ansys Workbench training in Coimbatore
Building Estimation and Costing training in Coimbatore
ProSteel training in Coimbatore
Revit Architecture training in Coimbatore
Staad Pro training in Coimbatore
This comment has been removed by the author.
ReplyDeleteI am very happy after reading this fantastic Article, I appereciate your work.
ReplyDeleteCSP Apply
CSP Online Application
Online CSP Apply
CSP Registration
CSP Online Application
CSP Provider
Digital India CSP
Kiosk Banking
Micro Finance
CSP Kiosk Banking
Utility Payment
Good
ReplyDeletePermutation and Combination Aptitude Interview Questions
Oracle Delete
Time and Work Aptitude Interview Questions
Chrome Flags Complete Guide Enhance Browsing Experience
Recursion and Iteration Programming Interview Questions
Apache Pig Subtract Function
Xml Serializer there was an Error Reflecting Type
Simple Interest Aptitude Interview Questions
Compound Interest Aptitude Interview Questions
Specimen Presentation of Letters Issued by Company
Bharat CSP is nothing but a business contributor and technology services provider to different kind of banks. Online Bank CSP Registration, Official Site for apply online CSP. Start Your Business. Mini Bank & Start Earning from 1st Month Low Investment Easy Process..
ReplyDeleteApply CSP
CSP registration
CSP provider
Top CSP Provider in India
Apply Online For Bank CSP
Online Money Transfer
very nice
ReplyDeleteinternship in chennai
ece internship
data science training in chennai
Internship in Chennai
Internship at Chennai
Internship Chennai
IT Internships
Online Internship
MBA internship
Thank you so much for this useful article. Visit OGEN Infosystem for Web Designing and SEO Services in Delhi, India.
ReplyDeleteSEO Service in Delhi
Very useful information, thanks for sharing with us
ReplyDeleteCorporate Training | Best Corporate Training | RAMSOL
Nice, Thanks for sharing
ReplyDeleteiot internships
inplant training in chennai
internship for automobile engineering students
internship for mca students in chennai
internship for eee students
internship for aeronautical engineering students
inplant training report for civil engineering
internship for ece students in chennai with stipend
summer training for ece students after second year
python internship
great.
ReplyDeleteAcceptance is to offer what a lighted
A reduction of 20 in the price of salt
Power bi resumes
Qdxm:sfyn::uioz:?
If 10^0.3010 = 2, then find the value of log0.125 (125) ?
A dishonest dealer professes to sell his goods at cost price but still gets 20% profit by using a false weight. what weight does he substitute for a kilogram?
Oops concepts in c# pdf
Resume for bca freshers
Attempt by security transparent method
'webmatrix.webdata.preapplicationstartcode.start()' to access security critical method 'system.web.webpages.razor.webpagerazorhost.addglobalimport(system.string)' failed.
Node js foreach loop
TVH is the best video & film Production houses in Delhi, India. We are Creative, positive and productive and create videos like Documentaries, Corporate films, Explainer videos etc. Moreover, we do Event management, Printing and Designing of all IEC, BCC and SBCC Material for all India regions. Being the best video production company in Delhi NCR, we aim to add creativity in each of our service offerings. If you want to make your company/brand stand out, Choose TVH as your partner communication management agency in Delhi NCR.
ReplyDeleteNice...
ReplyDeletedenmark web hosting
inplant training in chennai
ReplyDeleteWow!!! It was really an Informational Article which provide me with much Insightful Information. I would like to first thank the author for such an Insightful Content. If someone here is looking for a Website Designing Company in India, then look no further than Jeewangarg.com as we are the best website designing company in Delhi working in the arena for the last 8 years.
Best website designing company in India
website designing company in Delhi NCR
Google Partner in India
Hi,
ReplyDeleteIts a really useful Blog. Using this information with your given guidelines we can reduce usage of data network. This graph computing framework on hadoop is very easy and useful.
Wonderful Blog!!! Thnaks for sharing this great Post with us.
ReplyDeletePython Training in Chennai
Python course in Chennai
Python Training
Best Python Training Institute in Chennai
Python Training in Velachery
Python training in Adyar
Hadoop Training in Chennai
Software testing training in chennai
JAVA Training in Chennai
nice post...
ReplyDeletecoronavirus update
inplant training in chennai
inplant training
inplant training in chennai for cse
inplant training in chennai for ece
inplant training in chennai for eee
inplant training in chennai for mechanical
internship in chennai
online internships
This comment has been removed by the author.
ReplyDeleteGreat post....
ReplyDeleteCoronavirus Update
Intern Ship In Chennai
Inplant Training In Chennai
Internship For CSE Students
Online Internships
Internship For MBA Students
ITO Internship
usefull information....
ReplyDeletecoronavirus update
inplant training in chennai
inplant training
inplant training in chennai for cse
inplant training in chennai for ece
inplant training in chennai for eee
inplant training in chennai for mechanical
internship in chennai
online internship
Digital Marketing Services in Chennai
ReplyDeleteSEO Company in Chennai
SEO Consultant Chennai
CRO in Chennai
PHP Development in Chennai
Web Designing Chennai
Ecommerce Development Chennai
Thanks For Sharing the Articles,just Thanks Is not enough for all Keep Updating The Articles looking towards more
ReplyDeleteTo Learn Python and get a Consequence with Happy Then visit same
python training in chennai | python training in annanagar | python training in omr | python training in porur | python training in tambaram | python training in velachery
Thank you for the amazing value you are providing through your blog.
ReplyDeleteThanks for sharing Good Information
ReplyDeleteData science Training in bangalore
Aws Training In Bangalore
Hadoop Training In Bangalore
Your post is really awesome. It is very helpful for me to develop my skills in a right way.keep sharing such a worthy information.
ReplyDeleteAngular JS Training in Chennai | Certification | Online Training Course | Angular JS Training in Bangalore | Certification | Online Training Course | Angular JS Training in Hyderabad | Certification | Online Training Course | Angular JS Training in Coimbatore | Certification | Online Training Course | Angular JS Training | Certification | Angular JS Online Training Course
This is very interesting post and I learned so much from your blog. Do share more.
ReplyDeleteSelenium Training in Chennai
Selenium Training
Selenium Course in Chennai
Selenium Training Institute in Chennai
Selenium Online Training
Selenium Certification Training
I was looking at some of your posts on this website and I conceive this web site is really instructive! Keep putting up..
ReplyDeleteweb designing training in chennai
web designing training in omr
digital marketing training in chennai
digital marketing training in omr
rpa training in chennai
rpa training in omr
tally training in chennai
tally training in omr
Thanks for the information's about Hamburg, a graph computing framework on Hadoop .It's an Amazing Information...Thanks for Sharing with Us.
ReplyDeletedata science training in chennai
data science training in tambaram
android training in chennai
android training in tambaram
devops training in chennai
devops training in tambaram
artificial intelligence training in chennai
artificial intelligence training in tambaram
Very interesting information and this is very useful in my future. Please update them.
ReplyDeleteweb designing training in chennai
web designing training in annanagar
digital marketing training in chennai
digital marketing training in annanagar
rpa training in chennai
rpa training in annanagar
tally training in chennai
tally training in annanagar
Thanks for any other wonderful post. Where else may just anyone get that type of info in such a perfect means of writing? I’ve a presentation next week, and I am on the look for such information.
ReplyDeletejava training in chennai
java training in velachery
aws training in chennai
aws training in velachery
python training in chennai
python training in velachery
selenium training in chennai
selenium training in velachery
Informative content,thanks for sharing...waiting for next update.
ReplyDeleteibm training in chennai
ibm course in chennai
aix training in chennai
ibm course
ibm training
inplant course in chennai
Informative content,thanks for sharing...waiting for next update...
ReplyDeletejavascript training in chennai
javascript course in chennai
javascript training institute in chennai
Hibernate Training in Chennai
Html5 Training in Chennai
Good blog, it's really very informative, do more blogs under good concepts.
ReplyDeletewhat is use of python
ccna career opportunities
is python good for web development
skills required for machine learning
data science questions and answers pdf
Get instant assignment help service in Australia. We are in this service from last ten years and provide best assistance to all our clients. If you are in Australia and pursuing your graduation or post-graduation from over there, then you can get assistance from our experts. We believe in providing best to our clients to maintain a long relationship with our clients. You can expect from us a genuine work with zero plagiarism.
ReplyDeleteOnline Assignment Help
Pretty! This was an extremely wonderful post. Thanks for providing this information.
ReplyDeleteWebsite: panel chart
this article is very good. It is very so much valuable content. I hope these Commenting lists will help to my website
ReplyDeleteWebsite :- Electric hot water heater service in Nagpur
Great post, I think blog owners should larn a lot from this web blog its very user friendly.
ReplyDeleteVisit here :- Seo Packages In Gwalior
Very excellent post!!! Thank you so much for your great content. Keep posting.....
ReplyDeletePython Training Institute in Pune
Best Python Classes in Pune
Very interesting to read your blog. Good content delivery.
ReplyDeletehow to pass ielts exam
how to prepare for ielts exam
how to become a professional hacker
sample stress interview questions and answers
java concepts for selenium
ethical hacking interview questions and answers pdf
hacking books for beginners
Nice post! Thanks for your great content and I obtain a huge of knowledge from your best post...
ReplyDeleteSelenium with C# Training
Selenium with Python Training
Selenium with Java Training
Learn Selenium with C# Training
I am sure this paragraph has touched all the internet visitors, its really really fastidious piece of writing on building up new weblog.
ReplyDeleteonline electronics store in india
Great information, i was searching of this kind of information, thank you very much for sharing with us.
ReplyDeleteWebsite : Craigslist Posting Service for Car Dealers |
This was something I was looking for, really helpful, and great work is done. Thank you so much for sharing such valuable information.
ReplyDeleteWbsite : Car Auction Software |
https://www.mytectra.com/
ReplyDeleteThanks for sharing such a nice info.I hope you will share more information like this. please keep on sharing!
ReplyDeletePython Training In Bangalore
Artificial Intelligence Training In Bangalore
Data Science Training In Bangalore
Machine Learning Training In Bangalore
AWS Training In Bangalore
IoT Training In Bangalore
spend your time with our hot Escorts in Mumbai
ReplyDeleteMua vé máy bay tại Aivivu, tham khảo
ReplyDeletegiá vé máy bay đi Mỹ khứ hồi
giá vé máy bay thanh hóa sài gòn
vé máy bay từ đà lạt ra hà nội
vé máy bay rẻ đi nha trang
vé máy bay đi đà lạt bao nhiêu tiền
bảng giá taxi sân bay nội bài
Combo Nha Trang
Truly incredible blog found to be very impressive due to which the learners who ever go through it will try to explore themselves with the content to develop the skills to an extreme level. Eventually, thanking the blogger to come up with such an phenomenal content. Hope you arrive with the similar content in future as well.
ReplyDeleteschönen muttertag gif
Extraordinary blog! I recently went over your website and have found some interesting content.I am glad I found this amazing website on the web.
ReplyDeleteWebsite
I think that this article is very useful for the audience. It provides useful and quality information which is definitely going to help a lot of people.
ReplyDeleteClick Here
Finally, I found good quality and decent post, it is very helpful to me. I am grateful and thankful for all your effort and dedication.
ReplyDeleteBest CBSE School In Gorakhpur
Excellent article this article gives more useful information to us...
ReplyDeleteBug Screen in chennai
Best Quality uPVC windows and Doors in Chennai
Best Upvc Windows and doors dealers in chennai
This comment has been removed by the author.
ReplyDeleteIf your answer is yes to any one of the above questions, well don’t worry anymore. Because, no matter what kind of security challenge or threat you are facing, we have a bunch of professionals ready to get you out of the way of any harm. Be it your protection, your family’s safety, your bodyguard company
ReplyDeleteresidence or office security and surveillance, your asset protection, your transportation-related security needs, or even your chauffeur requirements, here’s a team that offers you comprehensive, highly efficient yet affordable solutions.
Good information regarding graph computing framework on Hadoop my sincere. Thanks for sharing please continue to share this post. Kinemaster Gold
ReplyDeleteThe share you really give us excitement. Thanks for your sharing. If you feel tired at work or study try to participate in our games to bring the most exciting feeling. Thank you! Kinemaster Gold
ReplyDeleteIt was a great blog with so much information of the beautiful places to visit.
ReplyDeletePest control provider in Nagpur
This is very useful software for you and me. No errors were found during the check.
ReplyDeleteYou can use it. I hope you like it.
Marketing and Advertising Graphics
Great post. keep sharing such a worthy information.
ReplyDeleteSwift Developer Course in Chennai
Swift Training in Bangalore
Learn Swift Online
It was not first article by this author as I always found him as a talented author. John Wayne Jacket
ReplyDeleteNice Article..!! Thanks for Sharing with us.
ReplyDeleteFor hand therapy exercise please visit squegg.
Thank you for sharing so insightful article. Rozana.in has a far-reaching presence across various cities in India.
ReplyDeleteVisit for more info local grocery stores
Hello there, You have done a great job. As we all know how much Bill of Sale being used. This document is usually used for sale and purchase between two parties like Buyer & seller.
ReplyDeleteVisit here colorado Bill of Sale
This post is so interactive and informative.keep update more information...
ReplyDeleteAWS Training in Anna Nagar
AWS Training in Chennai
Hey friend, it is very well written article, thank you for the valuable and useful information you provide in this post. Keep up the good work! FYI, Pet Care adda
ReplyDeleteCredit card processing, wimpy kid books free
,Essay About Trip With Family
This post is so interactive and informative.keep update more information...
ReplyDeletehadoop training in tambaram
Big data training in chennai
Nice Post, Good content
ReplyDeleteWeb development Company in Hyderabad- Inovies
Nice Post, Good content
ReplyDeleteWeb development Company in Hyderabad- Inovies
Ecommerce Development Company
Social Media Marketing Company in Hyderabad
Inovies is the best web development company in Hyderabad providing all types of services in web development, mobile app development, ios app development, ecommerce website development, web design.
It also provides digital marketing services like SEO, SEM, SMM etc.
The great website and information shared are also very appreciable. Young John Dutton Jacket
ReplyDeleteNice blog post so thanks a lot for sharing this great blog post.. keep more post for sharing.. have a nice day.
ReplyDeleteApply for Super Visa Canada
Thank You for Providing Such insightful information. If someone is looking for the Quickbooks Customer Service in US.
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteBest AWS Training provided by Vepsun in Bangalore for the last 12 years. Our Trainer has more than 20+ Years
ReplyDeleteof IT Experience in teaching Virtualization and Cloud topics.. we are very delighted to say that Vepsun is
the Top AWS cloud training Provider in Bangalore. We provide the best atmosphere for our students to learn.
Our Trainers have great experience and are highly skilled in IT Professionals. AWS is an evolving cloud
computing platform provided by Amazon with a combination of IT services. It includes a mixture of
infrastructure as service and packaged software as service offerings and also automation. We have trained
more than 10000 students in AWS cloud and our trainer Sameer has been awarded as the best Citrix and Cloud
trainer in india.
Visit Quickbooks Customer Service in US and find out QuickBooks is a software that helps you manage your business and track your income and expenses. It also helps you plan for future transactions, which in turn saves you time, money, and effort.
ReplyDeleteGreat post. keep sharing such a worthy information. Azure Data Factory Training in Hyderabad
ReplyDeleteThis is great content for your readers. Thanks for sharing.
ReplyDeleteflute for sale
Vedant Computer is Nagpur's 1st Ecommerce website for Refurbished Laptops, Refurbished Desktops, Providing consumers with an almost new-like experience.
ReplyDeleteVisit Here::- [url=https://vedabyte.com/]old laptop[/url]
Vedant Computer is Nagpur's 1st Ecommerce website for Refurbished Laptops, Refurbished Desktops, Providing consumers with an almost new-like experience.
ReplyDeleteVisit Here:- refurbished desktop
Hey! Nicely written , Intresting to read
ReplyDeletereact js training in hyderabad
thanks for valuable information
ReplyDeletenice ariticle
dellbhoomi training
Nice article
ReplyDeletevba macros course
advanced excel course
power bi course in hyderabad
microsoft office essentials course
advanced excel course in hyderabad
goodone
DeleteWe as an Adventure Travel company aim to show you nice people the most beautiful and pristine places in Karnataka. Preserving the cleanliness & beauty of our beautiful land is our topmost priority.
ReplyDeletekudremukha
This comment has been removed by the author.
DeleteNice Article..!! Thanks for Sharing with us.
ReplyDeleteAzure Data Factory Training in Hyderabad
Continue
ReplyDeleteContinue
Continue
Continue
A large portion of individuals have less number of jeans and more funny trending t-shirts. Thus, pants are normal generally speaking. Thus, remember you get the funny trending t-shirts that you wear with the entirety of your jeans. To close, these are a portion of the things that you ought to consider while you are looking for easygoing garments for men. You can go with the funny trending t- shirt assuming you need the best quality and fitting.
ReplyDeleteJoin top-rated React Training in Hyderabad to boost your web development skills. Interactive sessions, real-world projects, and expert instructors. Enroll now.
ReplyDelete"Great article, felt good after reading, worth it.
ReplyDeletei would like to read more from you.
keep posting more.
also follow Propmtengineeringcourseinhyderabad"
"Great article, felt good after reading, worth it.
ReplyDeletei would like to read more from you.
keep posting more.
also follow Mern Stack course in hyderabad"
"Top Digital Marketing Agency In Hyderabad
ReplyDelete"