The high-level organization of Pregel programs is inspired by Valiant's Bulk Synchronous Parallel model. Pregel computations consist of a sequence of iterations, called super-steps.
It's same with Hamburg design as figured below:
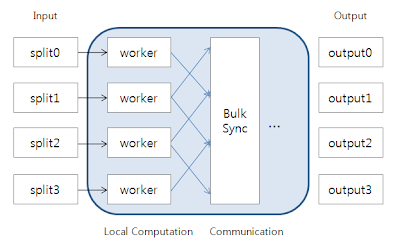
During a superstep the framework invokes a user-defined Compute() function for each vertex, conceptually in parallel. The function specifies behavior at a single vertex v and a single superstep S. It can read messages sent to v in superstep S - 1, send messages to other vertices that will be received at superstep S + 1, and modify the state of v and its outgoing edges. Messages are typically sent along outgoing edges, but a message may be sent to any vertex whose identifier is known. A program terminates when all vertices declare that they are done.
According to our reasoning, user defined Compute() function which can be called during graph traversal will be shaped as described below:
User Interface:
public void traverse(Map<Vertex, Message> value, Map<Integer, Message> nextQueue) {
for (Integer i : v.getAdjList()) {
// Handle the vertex and send a message with modified state of vertex i to next level
}
}
And, ... need something to local processing and send message to the next step.
So that's similar to the MapReduce model in that programmers focus on a local action, processing a single item at a time, which the system then lifts to computation on a large dataset.
Do you think everything was too easy this far? But, I can't say about below mechanisms and locality problems yet.
The basic computing model of Pregel is enhanced by several mechanisms to improve performance and usability. They include combiners, an optimization to reduce network traffic, and aggregators, a simple mechanism for monitoring and global communication.
And the conclusion is..
We conducted an experiment solving single-source shortest paths using a simple Belman-Ford algorithm expressed in Pregel. As input data, we chose a randomly generated graph with a log-normal distribution of outdegrees; the graph had 1B vertices and approximately 80B edges. Weights of all edges were set to 1 for simplicity. We used a cluster of 480 commodity multi-core PCs and 2000 workers. The graph was partitioned 8000 ways using the default partitioning function based on a random hash, to get a sense of the default performance of the Pregel system. Each worker was assigned 4 graph partitions and allowed up to 2 computational threads to execute the Compute() function over the partitions (not counting system threads that handle messaging, etc.). Running shortest paths took under 200 seconds, using 8 supersteps.
Belman-Ford algorithm computes single-source shortest paths in a weighted digraph. In the sub-graph, the passed path will be updated while compute() function is run to traversal. Then, the boundary of sub-graphs could synchronized by supersteps. This programming model can be more intuitional than M/R version BFS.
Anyway, though Hamburg isn't as good as pregel, It will be a great framework for many of graph techniques.
Note: Hamburg project integrated into Apache Hama.


I couldn't find any more specific information on Pregel, but it indeed seems like a rather trivial specialization of MapReduce, where the key for vertex data and for messages is the vertex ID.
ReplyDeleteIt is disappointing that the whitepaper does not describe the API (and potentially optimizations), since that is the most interesting part for a framework geared towards usability.
I wonder if the API has one or two steps:
-one step: Vertex Process(Vertex oldVertex, Inbox, Outbox), which reads from the Inbox and oldVertex, returns the new Vertex and writes messages in the Outbox
-two steps: Vertex ProcessIncoming(Vertex, Message[] Inbox) and Message[] SendMessages(Vertex)
Vertex would contain the list of neighboring vertices and other state information, as well as a flag for "done" (ie. no new "superstep" iteration needed).
The advantage of two steps is that ProcessIncoming can be used for optimizing the re-partitioning on vertex ID, as it can be used recursively, thereby reducing network traffic. The whitepaper only mentions a single user-defined function (Compute) but also mentions "handler" functions...
Vertices could be created and deleted by sending messages. These standard messages could be processed by handlers with default implementations.
Also, using a MapReduce trick, a dummy vertex with ID 0 can be used to collect the count of all vertices and all completed vertices.
Interesting! Thanks, I'll take a look at this.
ReplyDelete