Inference anatomy of the Google Pregel
The summary paper of the Google Pregel was distributed -- Pregel: a system for large-scale graph processing.
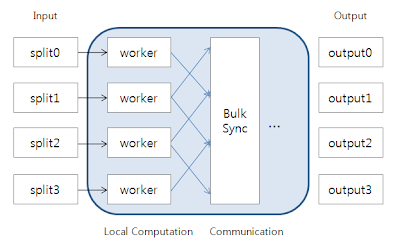
It's same with Hamburg design as figured below:
According to our reasoning, user defined Compute() function which can be called during graph traversal will be shaped as described below:
So that's similar to the MapReduce model in that programmers focus on a local action, processing a single item at a time, which the system then lifts to computation on a large dataset.
Do you think everything was too easy this far? But, I can't say about below mechanisms and locality problems yet.
And the conclusion is..
Belman-Ford algorithm computes single-source shortest paths in a weighted digraph. In the sub-graph, the passed path will be updated while compute() function is run to traversal. Then, the boundary of sub-graphs could synchronized by supersteps. This programming model can be more intuitional than M/R version BFS.
Anyway, though Hamburg isn't as good as pregel, It will be a great framework for many of graph techniques.
Note: Hamburg project integrated into Apache Hama.
The high-level organization of Pregel programs is inspired by Valiant's Bulk Synchronous Parallel model. Pregel computations consist of a sequence of iterations, called super-steps.
It's same with Hamburg design as figured below:

During a superstep the framework invokes a user-defined Compute() function for each vertex, conceptually in parallel. The function specifies behavior at a single vertex v and a single superstep S. It can read messages sent to v in superstep S - 1, send messages to other vertices that will be received at superstep S + 1, and modify the state of v and its outgoing edges. Messages are typically sent along outgoing edges, but a message may be sent to any vertex whose identifier is known. A program terminates when all vertices declare that they are done.
According to our reasoning, user defined Compute() function which can be called during graph traversal will be shaped as described below:
User Interface:
public void traverse(Map<Vertex, Message> value, Map<Integer, Message> nextQueue) {
for (Integer i : v.getAdjList()) {
// Handle the vertex and send a message with modified state of vertex i to next level
}
}
And, ... need something to local processing and send message to the next step.
So that's similar to the MapReduce model in that programmers focus on a local action, processing a single item at a time, which the system then lifts to computation on a large dataset.
Do you think everything was too easy this far? But, I can't say about below mechanisms and locality problems yet.
The basic computing model of Pregel is enhanced by several mechanisms to improve performance and usability. They include combiners, an optimization to reduce network traffic, and aggregators, a simple mechanism for monitoring and global communication.
And the conclusion is..
We conducted an experiment solving single-source shortest paths using a simple Belman-Ford algorithm expressed in Pregel. As input data, we chose a randomly generated graph with a log-normal distribution of outdegrees; the graph had 1B vertices and approximately 80B edges. Weights of all edges were set to 1 for simplicity. We used a cluster of 480 commodity multi-core PCs and 2000 workers. The graph was partitioned 8000 ways using the default partitioning function based on a random hash, to get a sense of the default performance of the Pregel system. Each worker was assigned 4 graph partitions and allowed up to 2 computational threads to execute the Compute() function over the partitions (not counting system threads that handle messaging, etc.). Running shortest paths took under 200 seconds, using 8 supersteps.
Belman-Ford algorithm computes single-source shortest paths in a weighted digraph. In the sub-graph, the passed path will be updated while compute() function is run to traversal. Then, the boundary of sub-graphs could synchronized by supersteps. This programming model can be more intuitional than M/R version BFS.
Anyway, though Hamburg isn't as good as pregel, It will be a great framework for many of graph techniques.
Note: Hamburg project integrated into Apache Hama.
Same matte black different feel -- Lamborghini LP640 vs BMW Z4 vs Hyundai Avante
Lamborghini LP640


2009 BMW Z4

And, Hyundai Avante ... Looks like burned car.



2009 BMW Z4

And, Hyundai Avante ... Looks like burned car.

Graph database on Hadoop
Below is the problem list of the recent trends of graph data in my Insight.
- Very large (e.g. Web linked data, Social network, ..., etc)
- Diversified attributes of node and edge
- Requires real-time processing (for exampe, finding the shortest path based on attributes in Google Map)
So, I'm thinking the graph database on hadoop as described below:
The large graph data can be stored on Hadoop/Hbase and, communication cost can be reduced by partitioning step as bulk processing. Then, finally we can perform the real-time graph processing. What do you think? ;)
- Very large (e.g. Web linked data, Social network, ..., etc)
- Diversified attributes of node and edge
- Requires real-time processing (for exampe, finding the shortest path based on attributes in Google Map)
So, I'm thinking the graph database on hadoop as described below:
HDFS Hama, Map/Reduce Hamburg
graph data -> graph partitioning for locality -> real-time processing
The large graph data can be stored on Hadoop/Hbase and, communication cost can be reduced by partitioning step as bulk processing. Then, finally we can perform the real-time graph processing. What do you think? ;)
Doug Cutting leaves Yahoo, joins Cloudera
The core member of Hadoop, Doug Cutting, is leaving Yahoo to join a startup called Cloudera. Cool... I would like to learn from his footsteps... and eventually soon be a open source developer like him.
The low-power Hadoop cluster
We're understand that the Hadoop is a low-cost way to manage and process the massive data since it has been designed to run on a lot of cheap commodity computers. But, the electric power costs also should be considered when evaluating cost effectiveness. Have you thought them? Since It's a fault tolerant system with active replication, a few servers could go anytime into power saving mode without data loss.
I heard that some guys are trying to handle this problem. See also : On the Energy (In)efficiency of Hadoop Clusters
I heard that some guys are trying to handle this problem. See also : On the Energy (In)efficiency of Hadoop Clusters
Subscribe to:
Posts (Atom)
-
 Opening the black box of Deep Neural Networks via Information - https://arxiv.org/pdf/1703.00810.pdf 지금까지 딥 러닝은 어떻게 동작하는지 이해할 수 없다고 믿어져왔다...
Opening the black box of Deep Neural Networks via Information - https://arxiv.org/pdf/1703.00810.pdf 지금까지 딥 러닝은 어떻게 동작하는지 이해할 수 없다고 믿어져왔다... -
음성 인공지능 분야에서 스타트업이 생각해볼 수 있는 전략은 아마 다음과 같이 3가지 정도가 있을 것이다: 독자적 Vertical 음성 인공지능 Application 구축 기 음성 플랫폼을 활용한 B2B2C 형태의 비지니스 구축 기 음성 플랫폼...
-
개발자 컨퍼런스같은 것도 방문한게 언제인지 까마득합니다. 코로나로 왠지 교류가 많이 없어졌습니다. 패스트캠퍼스로부터 좋은 기회를 얻어 강연을 하나 오픈하였습니다. 제가 강연에서 주로 다룰 내용은, 인터넷 역사 이래 발전해온 서버 사이드 기술들에 대해 ...