Hinton's CapsNet explains about entity's pose, lighting and deformation, instead of shape feature and pattern. While I reading Hinton's idea, I thought about Holonomic brain theory.
"If a holographic image, containing the image of an apple, is cut in half and then illuminated by a laser, each half will contain the overall image of the apple! Even if the halves are sliced again and again, from each little piece of the film can be restored the image of a whole apple (although the image will become less clear with the reduction of the parts)."
Our brain is also very similar. We don't store images in brain, we store some transformed code. We don't lose our memory, it just fade out.
Gear Watchface Designer on Mac OS X
재직 시절에 (싸게) 구매했던 기어 S3를 쓰다보면 watchface 권태기를 3개월마다 겪게 되는데, 그럴때마다 구매한게 지금 거진 20개 가까이 된다. 그런데 내 마음에 썩 들지도 않고 얼마 안하지만 아깝기도 해서 직접 만들어보기로 했다.
디자이너들을 위한 개발 도구는 Gear Watchface Designer를 검색해서 설치하면 되는데, Java 버전에 따라 키보드와 마우스가 먹통이 되는 현상이 있다. Java다 보니 뭐 맥북이든 윈도우즈든 상관은 없고, 최신버전 JDK에서는 동작하지 않고 반드시 JDK 8u151 [1] 버전을 설치해야 한다. 이것 때문에 개삽...
아래는 내가 지금 만들고 있는 watchface 인데, free 이미지를 활용해서 Roman 스타일로 내 맘에 꼭 든다 ㅋ 돈 받고 팔아봐야지~

[1]. JDK 8u151 버전 설치 링크: http://www.oracle.com/technetwork/java/javase/downloads/java-archive-javase8-2177648.html?printOnly=1
디자이너들을 위한 개발 도구는 Gear Watchface Designer를 검색해서 설치하면 되는데, Java 버전에 따라 키보드와 마우스가 먹통이 되는 현상이 있다. Java다 보니 뭐 맥북이든 윈도우즈든 상관은 없고, 최신버전 JDK에서는 동작하지 않고 반드시 JDK 8u151 [1] 버전을 설치해야 한다. 이것 때문에 개삽...
아래는 내가 지금 만들고 있는 watchface 인데, free 이미지를 활용해서 Roman 스타일로 내 맘에 꼭 든다 ㅋ 돈 받고 팔아봐야지~

Elegant Roman Javik 검색하면 나옴~
[1]. JDK 8u151 버전 설치 링크: http://www.oracle.com/technetwork/java/javase/downloads/java-archive-javase8-2177648.html?printOnly=1
Storm vs. Spark Streaming: 내부 메커니즘의 차이점
트렌드 면에서는 기계학습에 밀린 것 같지만, 실시간 처리 또는 스트리밍 처리는 대단히 중요한 기술이다. 오픈소스로 존재하는 Storm과 Spark을 한번 비교해보자. 물론 솔루션 선택은 자유이고, 상황에 맞는 것이 바로 최적의 솔루션이다.
1. Task Prallel vs. Data Parallel
계산 프로그래밍 모델에서부터 느낄 수 있는 가장 뚜렷한 차이는 먼저, Storm은 Task Parallelism이고 Spark Streaming은 Data Parallelism이다. 개인적으로는 보다 완성도 높은 시스템을 구현할 수 있는 Storm의 계산 그래프 구조를 선호하지만 코드의 복잡도 면에서는 Spark이 유리할 수 있다.
2. Streaming vs. Micro-batches
Spark streaming의 경우는 엄밀히 말하면 실시간 처리보다는 작은 단위의 배치 연속이라고 할 수 있다. Storm은 전형적인 event-driven record at a time processing model로써 살아있는 데이터를 처리한다고 하면, Spark은 휴면 상태로 넘어간 데이터를 처리한다. 때문에 Latency에서 차이가 발생하는데 Storm은 subsecond, Spark의 경우에는 사용자 임의지정 few seconds가 된다.
여기에서 중대한 차이점이 발생하는데, Storm의 경우에는 데이터 유실이 없어야 할 때 (no data loss), Spark은 중복 연산이 없어야할 때 (exactly once) 선택하는 것이 좋다.
한편, Storm Trident는 Micro-batches 스타일도 가능하다고 한다.

3. Stateless vs. Stateful
앞서 소개한대로 Storm은 매 레코드 별로 처리하기 때문에 State을 유지하지 않기 때문에 장애 복구 메커니즘이 Spark보다 복잡하고 re-launching 시간이 더 걸릴 것이다. Stateless vs. Stateful는 (뭔가 더 있을 것 같지만) 장애 복구 외의 차이점은 전혀 없다.
4. Integration with Batch processing
긴말 필요없이 당연히 Spark이 유리하겠다.
여기까지 알아봤고 과연 무엇이 최상의 솔루션인가? 내 생각엔 Storm이 조금 우수하다 판단한다. 물론 최적의 솔루션은 당신 상황에 맞아야 하겠다.
1. Task Prallel vs. Data Parallel
계산 프로그래밍 모델에서부터 느낄 수 있는 가장 뚜렷한 차이는 먼저, Storm은 Task Parallelism이고 Spark Streaming은 Data Parallelism이다. 개인적으로는 보다 완성도 높은 시스템을 구현할 수 있는 Storm의 계산 그래프 구조를 선호하지만 코드의 복잡도 면에서는 Spark이 유리할 수 있다.
2. Streaming vs. Micro-batches
Spark streaming의 경우는 엄밀히 말하면 실시간 처리보다는 작은 단위의 배치 연속이라고 할 수 있다. Storm은 전형적인 event-driven record at a time processing model로써 살아있는 데이터를 처리한다고 하면, Spark은 휴면 상태로 넘어간 데이터를 처리한다. 때문에 Latency에서 차이가 발생하는데 Storm은 subsecond, Spark의 경우에는 사용자 임의지정 few seconds가 된다.
여기에서 중대한 차이점이 발생하는데, Storm의 경우에는 데이터 유실이 없어야 할 때 (no data loss), Spark은 중복 연산이 없어야할 때 (exactly once) 선택하는 것이 좋다.
한편, Storm Trident는 Micro-batches 스타일도 가능하다고 한다.
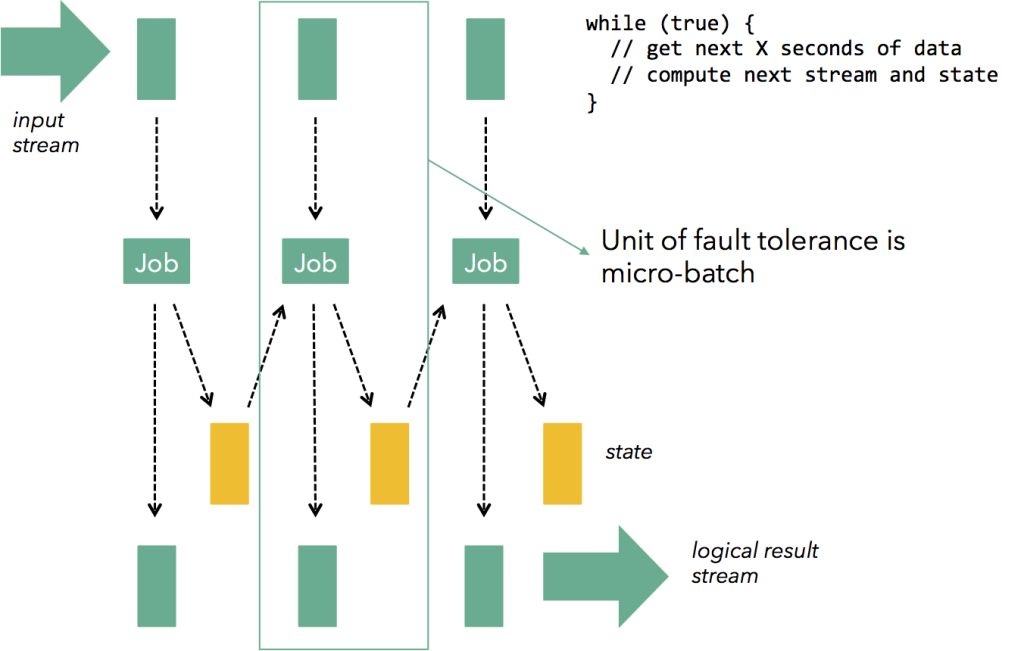
3. Stateless vs. Stateful
앞서 소개한대로 Storm은 매 레코드 별로 처리하기 때문에 State을 유지하지 않기 때문에 장애 복구 메커니즘이 Spark보다 복잡하고 re-launching 시간이 더 걸릴 것이다. Stateless vs. Stateful는 (뭔가 더 있을 것 같지만) 장애 복구 외의 차이점은 전혀 없다.
4. Integration with Batch processing
긴말 필요없이 당연히 Spark이 유리하겠다.
여기까지 알아봤고 과연 무엇이 최상의 솔루션인가? 내 생각엔 Storm이 조금 우수하다 판단한다. 물론 최적의 솔루션은 당신 상황에 맞아야 하겠다.
Subscribe to:
Posts (Atom)
-
 Opening the black box of Deep Neural Networks via Information - https://arxiv.org/pdf/1703.00810.pdf 지금까지 딥 러닝은 어떻게 동작하는지 이해할 수 없다고 믿어져왔다...
Opening the black box of Deep Neural Networks via Information - https://arxiv.org/pdf/1703.00810.pdf 지금까지 딥 러닝은 어떻게 동작하는지 이해할 수 없다고 믿어져왔다... -
음성 인공지능 분야에서 스타트업이 생각해볼 수 있는 전략은 아마 다음과 같이 3가지 정도가 있을 것이다: 독자적 Vertical 음성 인공지능 Application 구축 기 음성 플랫폼을 활용한 B2B2C 형태의 비지니스 구축 기 음성 플랫폼...
-
개발자 컨퍼런스같은 것도 방문한게 언제인지 까마득합니다. 코로나로 왠지 교류가 많이 없어졌습니다. 패스트캠퍼스로부터 좋은 기회를 얻어 강연을 하나 오픈하였습니다. 제가 강연에서 주로 다룰 내용은, 인터넷 역사 이래 발전해온 서버 사이드 기술들에 대해 ...