1. Task Prallel vs. Data Parallel
계산 프로그래밍 모델에서부터 느낄 수 있는 가장 뚜렷한 차이는 먼저, Storm은 Task Parallelism이고 Spark Streaming은 Data Parallelism이다. 개인적으로는 보다 완성도 높은 시스템을 구현할 수 있는 Storm의 계산 그래프 구조를 선호하지만 코드의 복잡도 면에서는 Spark이 유리할 수 있다.
2. Streaming vs. Micro-batches
Spark streaming의 경우는 엄밀히 말하면 실시간 처리보다는 작은 단위의 배치 연속이라고 할 수 있다. Storm은 전형적인 event-driven record at a time processing model로써 살아있는 데이터를 처리한다고 하면, Spark은 휴면 상태로 넘어간 데이터를 처리한다. 때문에 Latency에서 차이가 발생하는데 Storm은 subsecond, Spark의 경우에는 사용자 임의지정 few seconds가 된다.
여기에서 중대한 차이점이 발생하는데, Storm의 경우에는 데이터 유실이 없어야 할 때 (no data loss), Spark은 중복 연산이 없어야할 때 (exactly once) 선택하는 것이 좋다.
한편, Storm Trident는 Micro-batches 스타일도 가능하다고 한다.
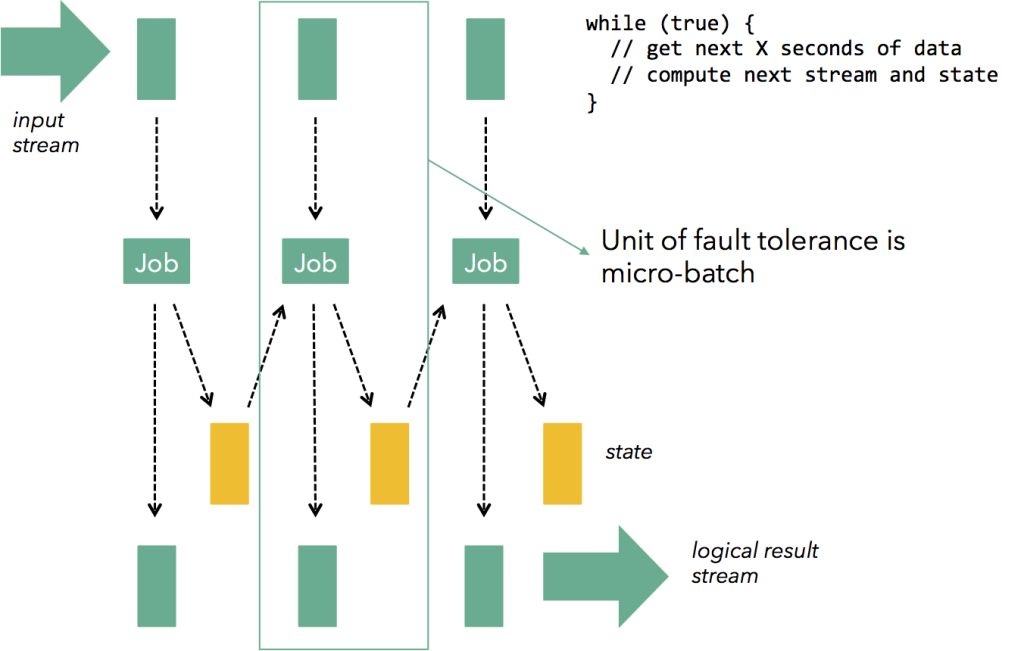
3. Stateless vs. Stateful
앞서 소개한대로 Storm은 매 레코드 별로 처리하기 때문에 State을 유지하지 않기 때문에 장애 복구 메커니즘이 Spark보다 복잡하고 re-launching 시간이 더 걸릴 것이다. Stateless vs. Stateful는 (뭔가 더 있을 것 같지만) 장애 복구 외의 차이점은 전혀 없다.
4. Integration with Batch processing
긴말 필요없이 당연히 Spark이 유리하겠다.
여기까지 알아봤고 과연 무엇이 최상의 솔루션인가? 내 생각엔 Storm이 조금 우수하다 판단한다. 물론 최적의 솔루션은 당신 상황에 맞아야 하겠다.

No comments:
Post a Comment