They tried to perform the matrix multiplication using MapReduce and CUBLAS. To avoid I/O bottlenecks during multiplication processing, a blocking/tiling algorithm was used based on M/R and, CUDA BLAS library (CUBLAS) was used for GPU acceleration in local computations. CUBLAS is a BLAS library ported to CUDA, which enables the use of fast computing by GPUs without direct operation of the CUDA drivers.
The interesting report is at this research, Pure java is better/faster when input (a split, or a sub-matrix in distributed system) is small.
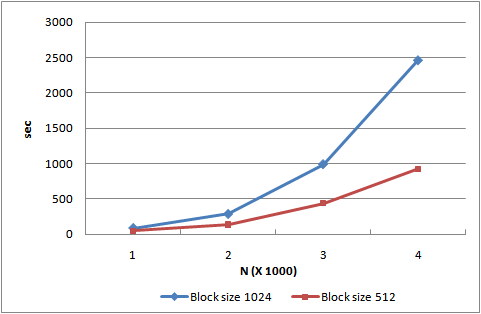

So, .. Perhaps it's not fit with distributed system, which is consist of a lot of nodes. But, I roughly guess that the GPU technology could be useful for future BSP concept of Apache Hama.
I'm not BSP expert yet, but I really love this phrase: "the BSGP program always has a significantly lower code complexity" from Bulk–Synchronous GPU Programming.

No comments:
Post a Comment